通信的代价
由于不太合群,之前很少和人做交流,处理事情的时候习惯单枪匹马地搞定。
但一个人的力量的力量是渺小的,集体的力量是庞大的,要成大事,还是需要找到适合自己的团队。如今进入团队工作,Leader 能够很好地向下兼容,因此不用担心太多。大家要开始整 TeamWork 啦,不可避免地要考虑各种通信 IO 的开销。假使大家做的事情类似(在同一个组内),磨合一段时间后便有了很多的共同话题——

遇到拿不定主意的时候,Leader 可以帮忙进行决策:

当面临跨组交流时,大家只清楚各自负责内容的细节,对外只暴露一个可调用的接口,彼此之间需要进行分工合作。此时我的心中有许多的疑惑:合作的目的是实现 1 + 1 > 2 的效果,但如果把这个计算单位看成是效率上的延迟,一切仿佛就成了很不可接受的现实。假使这是在创业小规模团队中的一个需求,大家都知道具体细节,一拍脑袋就可以决定立即执行某件事情,高效完成,然后快速交付。但这样的任务(Task)在大体量的公司中难以计数,不可能时时刻刻都有人(或者说这样的资源)能拍脑袋做出正确的决策,所以架构中就引入了负责管理和调度的团队,将执行过程的上下文做了更具体拆分。
但人与人之间的通信总是要有代价的,一旦流程变得复杂,引入了额外的切换开销,在出问题后就更难快速而精准地定位到具体的环节。若是日常事务的交谈,从情绪上兼容其他人是很简单的一件事情,可想要把它给落实到项目上,远没有想象中简单。 我想到了 NIPS 2015 的一篇文章:《Hidden Technical Debt in Machine Learning Systems》。
里面有很多经典示意图:
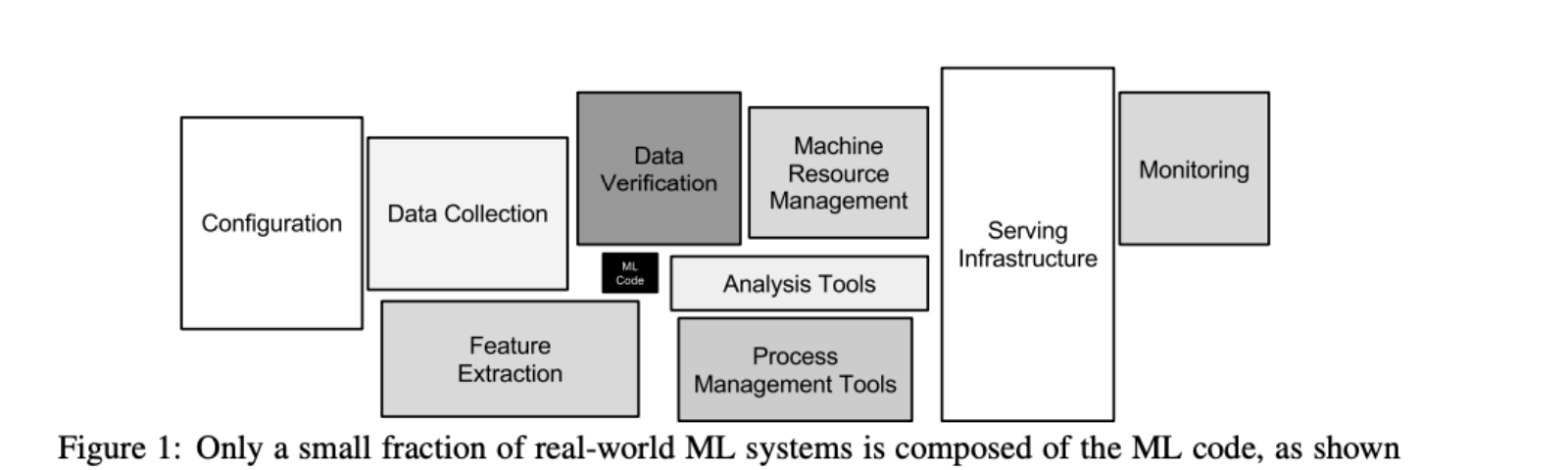
从算法到实际业务的落地,里面有太多太多的细节,是实际去做了才能体会的。
今年 9 月 22 日,Andrew 在 Stanford HAI Seminar 上做了一期名为《Bridging AI's Proof-of-Concept to Production Gap》的分享,很多经验来自于 AI Fund. 如果任务拆分过于笼统,可能会出现一个人搞不定的情况;如果任务拆分过于细化,在加大人力投入的同时,也引入了高昂的通信代价。今天的苹果发布会上,发布了 M1 芯片和相应的产品,最吸引我的一项设计是 Unified memory architecture, 即让 GPU 和 CPU 共享相同的内存,这样数据不用通过 PCIe 总线进行交换(准确来说是 Memory Copy),就能够进行更加高效的处理。
CPU 组只负责做 CPU 该干的活,GPU 组也不例外,采用传统的架构来做一件事情,如果同时需要用到 CPU 和 GPU,两个组在数据交换的时候就需要在总线上拉会讨论。内存数据拷贝的开销是非常大的,不仅是计算效率的开销大(相较于浮点计算),还引入了过多的能量消耗。现在的统一内存架构就很香,大家彼此之间的信息是同步的,具体怎么去处理,就各凭本事了。之前一直很抵触学习计算机架构方面的知识,停留在操作系统应用层面就不再深挖,如今觉得:“哦~我的老伙计,你看这新的架构,它真美呀。哦~我的意思是,上帝呀,谁要是再用以前那老掉牙的架构设计,我一定要用靴子狠狠地踢他的屁股。”
最后从全局上来回顾一下这件事情,在做一件事情的时候,仅仅局限于当下的需求,很容易造成整体设计上的灾难,学会向前看和向后看都很重要。可能骨子里已然形成了一种偏执,我总是倾向于认为自己的方案从全局上看是对的。这种莫名自信的来源也很简单:我的向前看不仅仅是看在此之前有什么样的成熟项目值得借鉴,我们应该把从出生到现在所有的见识给连结起来,读过的书、听过的歌、看过的电影、见过的人,都有可能对当前的决策和行为产生有益的影响。乔布斯在 05 斯坦福毕业典礼所说的点连成线,就是这个道理。